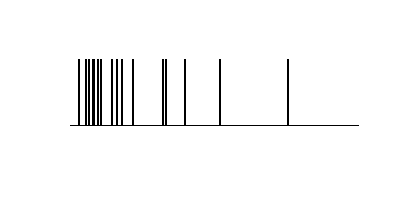データの準備
約10万文献を使用。
下記を参照。
touch-sp.hatenablog.com
トピックモデルの作成
library(text2vec) #データの読み込み new_stopwords <- readRDS("new_stopwords") Absts <- readLines("Absts_train.txt") #単語の抽出 it <- itoken(Absts, tolower, word_tokenizer) voc <- create_vocabulary(it, stopwords = new_stopwords) voc <- prune_vocabulary(voc, doc_count_min = 5L) voc <- voc[!grepl("^[0-9]*$", voc$term),] dtm <- create_dtm(it, vocab_vectorizer(voc)) lda_model <- LDA$new(n_topics = 10, doc_topic_prior = 0.1, topic_word_prior = 0.01) doc_topic_distr <- lda_model$fit_transform(x = dtm, n_iter = 1000, convergence_tol = 0.001, n_check_convergence = 25, progressbar = FALSE)
新しいデータに適応
pmid <- readLines("PMID_456.txt") Absts <- readLines("Absts_456.txt") cq = "smoking increase risk mortality cardiovascular disease development renal failure patient with CKD" #データにCQを追加 Absts <- c(cq, Absts) pmid <- c("0000", pmid) it <- itoken(Absts, tolower, word_tokenizer, ids = pmid) dtm <- create_dtm(it, vocab_vectorizer(voc)) new_topic <- lda_model$transform(dtm) answer <- new_topic["0000",, drop = FALSE] cos_sim <- sim2(x = new_topic, y = answer, method = "cosine", norm = "l2") result <- sort(cos_sim[, 1], decreasing = TRUE)[-1]
結果の確認
seikai <- readLines("seikai.txt") bar <- names(result) %in% seikai barplot(bar, axes = F)
もともとのばらつき。
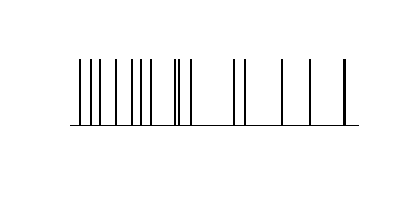
実施後。
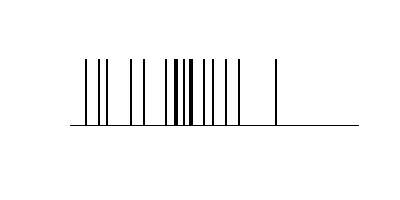
データ加工
library(tm) Absts <- stemDocument(Absts, "en") voc <- prune_vocabulary(voc, doc_count_min = 10L)
もともとのばらつき。
データ加工なし。
データ加工あり。
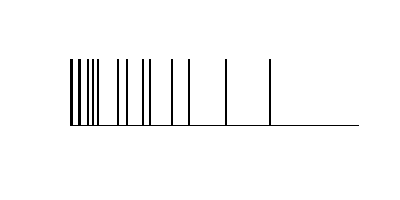
トピック数を増やす
lda_model <- LDA$new(n_topics = 20, doc_topic_prior = 0.1, topic_word_prior = 0.01)
もともとのばらつき。
トピック数10
トピック数を増やす。(n=20)
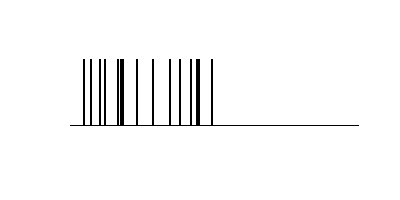
さらにトピック数を増やす
lda_model <- LDA$new(n_topics = 30, doc_topic_prior = 0.1, topic_word_prior = 0.01)
もともとのばらつき。
トピック数を増やす。(n=20)
さらにトピック数を増やす。(n=30)