今回使用したデータ
miniJSRT_database | 日本放射線技術学会 画像部会から「Segmentation > >Segmentation01(256×256,RGB Color:24bit)」をダウンロードさせて頂きました。学習データ50画像、テストデータ10画像です。
学習データが少ないですがAugmentationで増やせということでしょうか?
学習スクリプト
ラベル画像に影響しないAugmentation(RandomColorJitterとRandomLighting)だけ使用しました。回転や上下反転、左右反転などはラベル画像にも変換を加える必要があるため使用しませんでした。
学習率はデフォルトのままです。
auxiliary lossを使用しています。
import mxnet as mx from mxnet import gluon, image, autograd from mxnet.gluon.data.vision import transforms import gluoncv ctx = mx.gpu() if mx.context.num_gpus() >0 else mx.cpu() jitter_param = 0.4 lighting_param = 0.1 input_transform = transforms.Compose([ transforms.RandomColorJitter(brightness=jitter_param, contrast=jitter_param, saturation=jitter_param), transforms.RandomLighting(lighting_param), transforms.ToTensor(), transforms.Normalize([.485, .456, .406], [.229, .224, .225]), ]) img_list = [] label_list = [] for i in range(1, 51): img = image.imread('seg_image/train/org/%d.png'%i) img_list.append(img) label = image.imread('seg_image/train/label/%d.png'%i, flag=0) label = label/255 label_list.append(mx.nd.squeeze(label)) train_dataset = gluon.data.dataset.ArrayDataset(img_list, label_list) train_dataloader = gluon.data.DataLoader( train_dataset.transform_first(input_transform), batch_size=4 , shuffle=True) model = gluoncv.model_zoo.FCN( root = './models', nclass = 2, backbone = 'resnet50', aux = True, ctx = ctx, pretrained_base=True, crop_size=256) criterion = gluoncv.loss.MixSoftmaxCrossEntropyLoss(aux=True) trainer = gluon.Trainer(model.collect_params(), 'sgd') epochs = 50 for epoch in range(1, epochs + 1): train_loss = 0.0 data_count = 0 for i, (data, target) in enumerate(train_dataloader): with autograd.record(): outputs = model(data.as_in_context(ctx)) losses = criterion(outputs[0], outputs[1], target.as_in_context(ctx)) losses.backward() trainer.step(data.shape[0]) data_count += data.shape[0] train_loss += mx.nd.sum(losses).asscalar() print('Epoch %d, batch %d[%d/%d], training loss %.3f'%(epoch, i+1, data_count, len(train_dataset), train_loss/data_count)) model.save_parameters('seg.params')
結果
Epoch 1, batch 1[4/50], training loss 1.014 Epoch 1, batch 2[8/50], training loss 0.873 Epoch 1, batch 3[12/50], training loss 0.804 Epoch 1, batch 4[16/50], training loss 0.767 Epoch 1, batch 5[20/50], training loss 0.743 ・ ・ ・ Epoch 50, batch 9[36/50], training loss 0.104 Epoch 50, batch 10[40/50], training loss 0.103 Epoch 50, batch 11[44/50], training loss 0.102 Epoch 50, batch 12[48/50], training loss 0.102 Epoch 50, batch 13[50/50], training loss 0.102
テスト画像を用いた評価
import glob import numpy as np from PIL import Image import mxnet as mx import gluoncv from mxnet import image from mxnet.gluon.data.vision import transforms ctx = mx.gpu() if mx.context.num_gpus() >0 else mx.cpu() input_transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize([.485, .456, .406], [.229, .224, .225]), ]) model = gluoncv.model_zoo.FCN( root = './models', nclass = 2, backbone = 'resnet50', aux = True, ctx = ctx, pretrained_base=True, crop_size=256) model.load_parameters('seg.params') img_files = glob.glob('./seg_image/test/org/*.png') for i, img_file in enumerate(img_files): img = image.imread(img_file) img_PIL = Image.fromarray(img.asnumpy()) img = input_transform(img) output = model.predict(img.expand_dims(0).as_in_context(ctx)) output = mx.nd.squeeze(output) prediction = np.argmax(output.asnumpy(), axis=0).astype('int8') prediction = prediction * 255 mask = Image.fromarray(prediction).convert('RGB') mask.putalpha(60) img_PIL.paste(mask, mask) img_PIL.save('result_%d.png'%i)
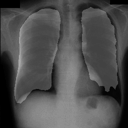
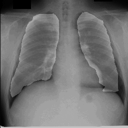
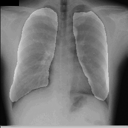
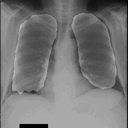
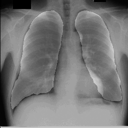
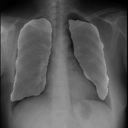
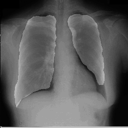
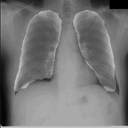
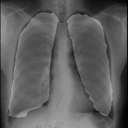
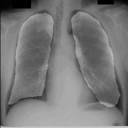
感想
たった50画像を学習しただけですがなかなかの結果になったと思います。動作環境
Windows 10 with NVIDIA GTX 1080 Python 3.7.9
atomicwrites==1.4.0 attrs==20.3.0 autocfg==0.0.6 autogluon.core==0.0.16b20210204 autograd==1.3 bcrypt==3.2.0 boto3==1.17.1 botocore==1.20.1 certifi==2020.12.5 cffi==1.14.4 chardet==3.0.4 click==7.1.2 cloudpickle==1.6.0 colorama==0.4.4 ConfigSpace==0.4.16 cryptography==3.3.1 cycler==0.10.0 Cython==0.29.21 dask==2021.1.1 decord==0.4.2 dill==0.3.3 distributed==2021.1.1 future==0.18.2 gluoncv==0.9.2 graphviz==0.8.4 HeapDict==1.0.1 idna==2.6 importlib-metadata==3.4.0 iniconfig==1.1.1 jmespath==0.10.0 joblib==1.0.0 kiwisolver==1.3.1 matplotlib==3.3.4 msgpack==1.0.2 mxnet-cu102==1.7.0 numpy==1.16.6 opencv-python==4.5.1.48 packaging==20.9 pandas==1.2.1 paramiko==2.7.2 Pillow==8.1.0 pluggy==0.13.1 portalocker==2.2.1 protobuf==3.14.0 psutil==5.8.0 py==1.10.0 pyaml==20.4.0 pycparser==2.20 PyNaCl==1.4.0 pyparsing==2.4.7 pytest==6.2.2 python-dateutil==2.8.1 pytz==2021.1 pywin32==300 PyYAML==5.4.1 requests==2.25.1 s3transfer==0.3.4 scikit-learn==0.23.2 scikit-optimize==0.8.1 scipy==1.4.1 six==1.15.0 sortedcontainers==2.3.0 tblib==1.7.0 tensorboardX==2.1 threadpoolctl==2.1.0 toml==0.10.2 toolz==0.11.1 tornado==6.1 tqdm==4.56.0 typing-extensions==3.7.4.3 urllib3==1.26.3 yacs==0.1.8 zict==2.0.0 zipp==3.4.0
2021年2月7日追記
さらに良い結果を求めたのがこちらになります。touch-sp.hatenablog.com