公開日:2023年1月21日
最終更新日:2023年2月2日
やりたいこと
今回やりたかったことはファインチューニングしたモデルに「sks robo」というpromptを与えて以下のようなオリジナルのロボットを出力することです。
「sks」は適当な文字列です。
ロボットは子供にブロックを借りて適当に自分が作ったものです。
はじめに
前回Textual Inversionという手法でStable Diffusion v1.4のファインチューニングを行いました。touch-sp.hatenablog.com
Textual Inversionでは自分好みの物体を出力するのは難しい印象です。
今回はLoRA(Low-Rank Adaptation)を試してみました。
基本的には後述する公式チュートリアル通りに実行しただけです。
環境構築
PC環境
WindowsとWSL2の二つの環境で動作確認できています。Windows
Windows 11 CUDA 11.6.2 Python 3.10.9
WSL2
Ubuntu 20.04 on WSL2 (Windows 11) CUDA 11.6.2 Python 3.8.10
Python環境の構築
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116 pip install diffusers==0.12.1 pip install transformers==4.26.0 pip install accelerate==0.16.0 datasets==2.8.0 ftfy==6.1.1 tensorboard==2.11.2 Jinja2==3.1.2
事前準備
Stable Diffusion v1.4のダウンロード
git lfs install git clone https://huggingface.co/CompVis/stable-diffusion-v1-4
Pythonスクリプトのダウンロード
こちらから「Source code(zip)」をダウンロードしてその中の「train_dreambooth_lora.py」を使用させて頂きました。「diffusers-0.12.1/examples/dreambooth/」フォルダ内にあります。
使用する画像を準備する
このような6枚の画像を用意しました。PowerPointを用いて1枚1枚手作業で背景を白にしています。

もともと縦横比1:1の画像を用意しましたが別にそうでなくても大丈夫です。
ただし強制的にリサイズされるので1:1にしておく方が無難と思います。
実行
accelerateの設定
accelerate config
------------------------------------------------------------------------------------------------------------------------ In which compute environment are you running? This machine ------------------------------------------------------------------------------------------------------------------------ Which type of machine are you using? No distributed training Do you want to run your training on CPU only (even if a GPU is available)? [yes/NO]:NO Do you wish to optimize your script with torch dynamo?[yes/NO]:NO Do you want to use DeepSpeed? [yes/NO]: NO What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:all ------------------------------------------------------------------------------------------------------------------------ Do you wish to use FP16 or BF16 (mixed precision)? bf16
「prior-preservation loss」あり・なしの両方で学習しました。
no prior-preservation loss
初回学習
accelerate launch train_dreambooth_lora.py \ --pretrained_model_name_or_path="stable-diffusion-v1-4" \ --instance_data_dir="robo" \ --output_dir="lora_robo" \ --instance_prompt="a photo of sks robo" \ --resolution=512 \ --train_batch_size=1 \ --sample_batch_size=1 \ --gradient_accumulation_steps=1 \ --gradient_checkpointing \ --learning_rate=1e-4 \ --lr_scheduler="constant" \ --lr_warmup_steps=0 \ --checkpointing_steps=100 \ --max_train_steps=200
学習終了後に以下のエラーが出ますが無視して問題ないです。
raise subprocess.CalledProcessError(returncode=process.returncode, cmd=cmd)
学習結果はちゃんと保存さているはずです。
学習の再開
accelerate launch train_dreambooth_lora.py \ --pretrained_model_name_or_path="stable-diffusion-v1-4" \ --instance_data_dir="robo" \ --output_dir="lora_robo" \ --instance_prompt="a photo of sks robo" \ --resolution=512 \ --train_batch_size=1 \ --sample_batch_size=1 \ --gradient_accumulation_steps=1 \ --gradient_checkpointing \ --learning_rate=1e-4 \ --lr_scheduler="constant" \ --lr_warmup_steps=0 \ --checkpointing_steps=100 \ --max_train_steps=800 \ --resume_from_checkpoint="latest"
with a prior-preservation loss
初回学習
accelerate launch train_dreambooth_lora.py \ --pretrained_model_name_or_path="stable-diffusion-v1-4" \ --instance_data_dir="robo" \ --instance_prompt="a photo of sks robo" \ --output_dir="lora_robo_with_prior-preserving" \ --with_prior_preservation --prior_loss_weight=1.0 \ --class_data_dir="robo-class-images" \ --class_prompt="a photo of robo" \ --num_class_images=200 \ --resolution=512 \ --train_batch_size=1 \ --sample_batch_size=1 \ --gradient_accumulation_steps=1 \ --gradient_checkpointing \ --learning_rate=1e-4 \ --lr_scheduler="constant" \ --lr_warmup_steps=0 \ --checkpointing_steps=100 \ --max_train_steps=200
学習の再開
accelerate launch train_dreambooth_lora.py \ --pretrained_model_name_or_path="stable-diffusion-v1-4" \ --instance_data_dir="robo" \ --instance_prompt="a photo of sks robo" \ --output_dir="lora_robo_with_prior-preserving" \ --with_prior_preservation --prior_loss_weight=1.0 \ --class_data_dir="robo-class-images" \ --class_prompt="a photo of robo" \ --resolution=512 \ --train_batch_size=1 \ --sample_batch_size=1 \ --gradient_accumulation_steps=1 \ --gradient_checkpointing \ --learning_rate=1e-4 \ --lr_scheduler="constant" \ --lr_warmup_steps=0 \ --checkpointing_steps=100 \ --max_train_steps=400 \ --resume_from_checkpoint="latest"
推論
from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler import torch import argparse parser = argparse.ArgumentParser() parser.add_argument( '--model', required=True, type=str, help='model id' ) opt = parser.parse_args() pipe = DiffusionPipeline.from_pretrained("stable-diffusion-v1-4", torch_dtype=torch.float16) pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config) pipe.to("cuda") lora_id = opt.model pipe.unet.load_attn_procs(lora_id) def null_safety(images, **kwargs): return images, False pipe.safety_checker = null_safety seed = 200 for i in range(4): new_seed = seed + i generator = torch.manual_seed(new_seed) image = pipe( prompt = "sks robo on the beach", num_inference_steps = 50, generator = generator, num_images_per_prompt = 1).images[0] image.save(f'{lora_id}_{new_seed}.png')
結果
全体的に暗くなったのは元の写真が暗いからだと思われます。別に明るい写真を使った場合の結果を最後に載せておくのでそちらもぜひ見て下さい。上記の推論スクリプトを使っています。seedを固定して4枚出力しました。たくさんの出力結果から良いものを選んだわけではありません。seedを変えればもっといい画像ができる可能性もあります。
no prior-preservation loss
steps 400

steps 800(今回はこのあたりがベストだと思います)

steps 1200

with a prior-preservation loss
steps 400

steps 800
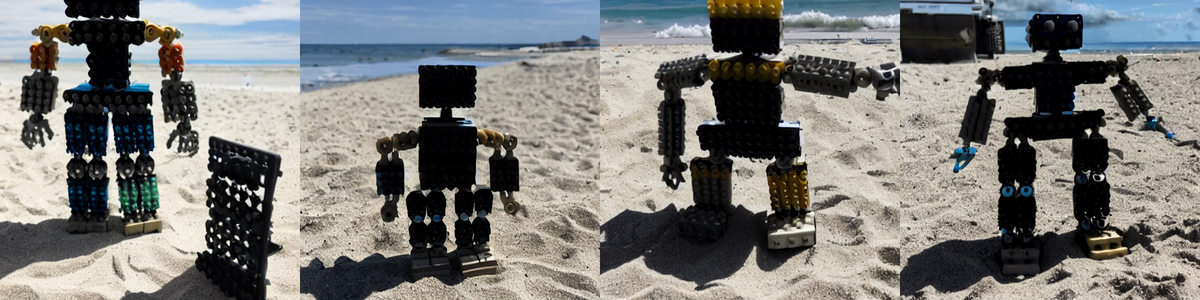
steps 1200
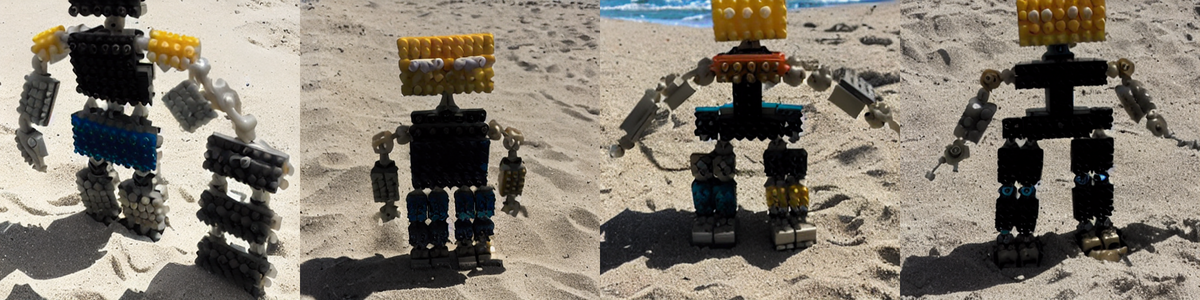
公式チュートリアル
github.comその他
RTX 3080 VRAM 12GBで学習可能で、学習時間は数分でした。prior-preservation lossを使用しなければVRAM使用量は8GB未満でした。8GBのVRAMでもいけるかもしれません。prior-preservation lossを使用した場合のVRAM使用量は9~10GBでしたので8GBでは難しいです。10GBでギリギリ行けると思います。「bitsandbytes」「xformers」「deepspeed」などを使うとVRAM使用量は減らせるらしいですが、やってみてあまり変わらない印象でした。これに関しては自分のやり方が不十分だった可能性があります。
追加の実験①
全体的に暗い出力になってしまったので写真を明るいものに変更しました。用意した枚数は7枚です。画像はこちらからダウンロード可能です。
「prior-preservation loss」ありで1600stepsの学習を行いました。

下記のもともとの写真とそれほど変わらない出力が得られています。
ただし、ビーチの描写が貧弱になっているので過学習していると思います。
その証拠にpromptを「sks robo in New York」などと変更してみても背景がほとんど描写されません。
そこで、ロボットクラスとして用意した正則化画像を200枚から400枚に増やしてみました。

今度はビーチがちゃんと描写されており過学習が防げていると思います。
追加の実験②
新たな記事を書きました。touch-sp.hatenablog.com