公開日:2023年2月3日
最終更新日:2023年2月13日
はじめに
長らくDiffusersのDreamBoothでxFormersがうまく機能しない時期がありました。「xformers==0.0.17.dev441」が公開されてその問題は解決したようです。さっそくVRAM 12GBのRTX 3080でDreamBoothが実行可能か調べてみました。環境構築
「bitsandbytes」を併用するためWSL2を使っています。Ubuntu 20.04 on WSL2 (Windows 11) RTX 3080 Laptop VRAM 16GB CUDA 11.6.2 Python 3.8.10
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116 pip install git+https://github.com/huggingface/diffusers.git pip install transformers==4.26.1 pip install accelerate==0.16.0 scipy==1.10.0 datasets==2.8.0 ftfy==6.1.1 tensorboard==2.11.2 pip install xformers==0.0.17.dev447 pip install triton==2.0.0.dev20230208 pip install bitsandbytes==0.37.0
設定
accelerate config
------------------------------------------------------------------------------------------------------------------------In which compute environment are you running? This machine ------------------------------------------------------------------------------------------------------------------------Which type of machine are you using? No distributed training Do you want to run your training on CPU only (even if a GPU / Apple Silicon device is available)? [yes/NO]:NO Do you wish to optimize your script with torch dynamo?[yes/NO]:NO Do you want to use DeepSpeed? [yes/NO]: NO What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:all ------------------------------------------------------------------------------------------------------------------------Do you wish to use FP16 or BF16 (mixed precision)? fp16
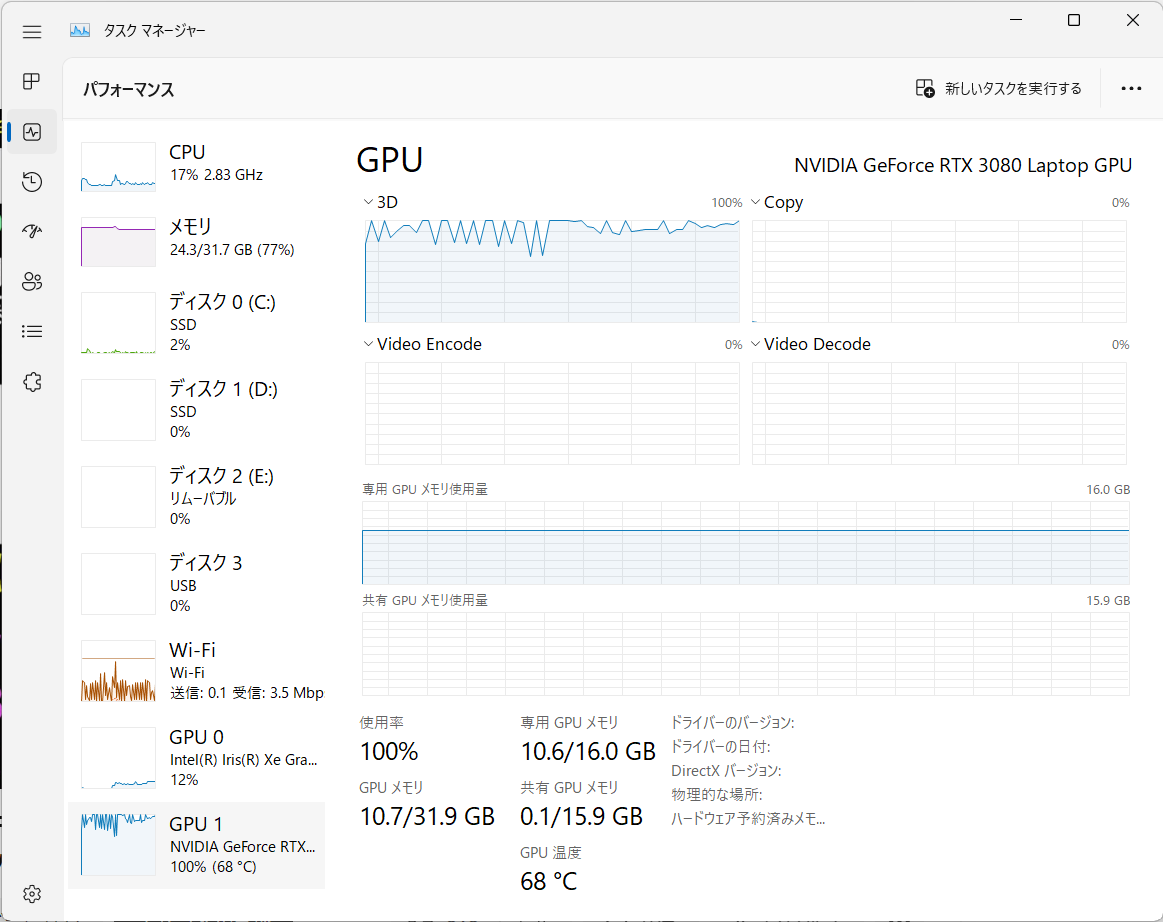
text encoderのファインチューニングなし
accelerate launch train_dreambooth.py \ --pretrained_model_name_or_path="stable-diffusion-v1-4" \ --instance_data_dir="RoboData" \ --output_dir="dreambooth_robo" \ --instance_prompt="a photo of sks robo" \ --resolution=512 \ --train_batch_size=1 \ --gradient_accumulation_steps=1 \ --learning_rate=5e-6 \ --lr_scheduler="constant" \ --lr_warmup_steps=0 \ --checkpointing_steps=100 \ --max_train_steps=200 \ --enable_xformers_memory_efficient_attention \ --gradient_checkpointing \ --set_grads_to_none \ --use_8bit_adam \ --with_prior_preservation --prior_loss_weight=1.0 \ --class_data_dir="robo-class-images" \ --class_prompt="a photo of robo" \ --num_class_images=400
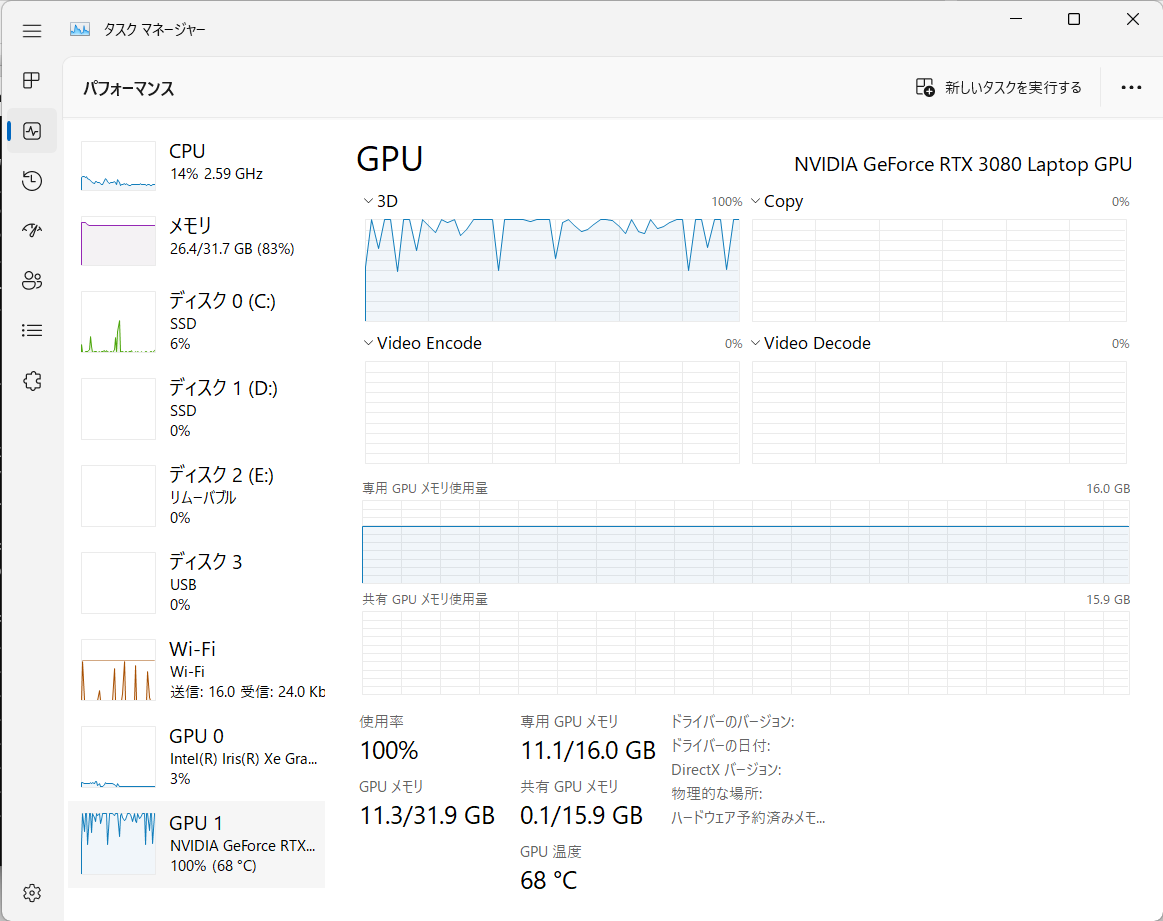
text encoderのファインチューニングあり
accelerate launch train_dreambooth.py \ --pretrained_model_name_or_path="stable-diffusion-v1-4" \ --instance_data_dir="RoboData" \ --output_dir="dreambooth_robo" \ --instance_prompt="a photo of sks robo" \ --resolution=512 \ --train_batch_size=1 \ --gradient_accumulation_steps=1 \ --learning_rate=5e-6 \ --lr_scheduler="constant" \ --lr_warmup_steps=0 \ --checkpointing_steps=100 \ --max_train_steps=200 \ --enable_xformers_memory_efficient_attention \ --gradient_checkpointing \ --set_grads_to_none \ --use_8bit_adam \ --with_prior_preservation --prior_loss_weight=1.0 \ --class_data_dir="robo-class-images" \ --class_prompt="a photo of robo" \ --num_class_images=400 \ --train_text_encoder
現時点での結論
VRAM 12GBあればtext encoderの学習も含めてDreamBoothの実行は可能でした。結果
今回の検証とは関係ありませんが一応結果を残しておきます。以下の結果をみるとtext encoderのファインチューニングを行うと容易に過学習におちいるのではないかと思います。ともに学習率 1e6で学習しています。text encoderのファインチューニングなし
400steps

800steps

text encoderのファインチューニングあり
200steps

400steps

800steps

関連記事
touch-sp.hatenablog.comtouch-sp.hatenablog.com
touch-sp.hatenablog.com