特徴
今わかっている特徴は- 簡単に使える
- いろんなモデルが使える
- ControlNetが使える
注意点
VRAM使用は11~12GBでした。VRAM 12GBのRTX 3080で動作確認しています。さっそく使ってみる
simple Text-To-Video
非常に簡潔なスクリプトで実行可能です。import torch from model import Model model = Model(device = "cuda", dtype = torch.float16) model.process_text2video( prompt="A horse galloping on a street", fps = 4, path = "result.mp4", chunk_size = 2, video_length = 20)
たったのこれだけです。512x512で5秒の動画が作成されます。

事前準備は環境構築のみです。環境構築は後述します。
デフォルトで「dreamlike-art/dreamlike-photoreal-2.0」が使われます。モデルのダウンロードは自動で行われます。
他のモデルを使用したい場合にはこのようにします。
ローカルにダウンロードしている「Anything-v4.0」を使った例です。
import torch from model import Model model = Model(device = "cuda", dtype = torch.float16) model.process_text2video( prompt="A horse galloping on a street", model_name= "local_model/anything-v4.0", fps = 4, path = "result.mp4", chunk_size = 2, video_length = 20)
Text-To-Video with ControlNet
ControlNetの「canny2image」とAnything-v4.0を組み合わせて作成した動画がこちらです。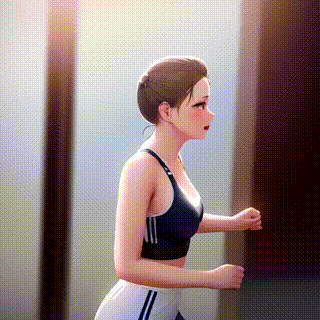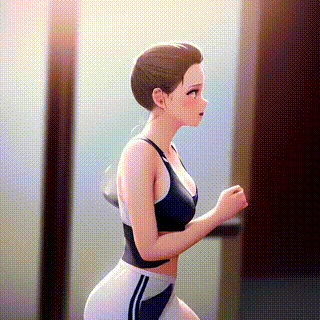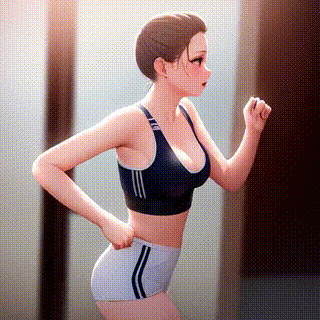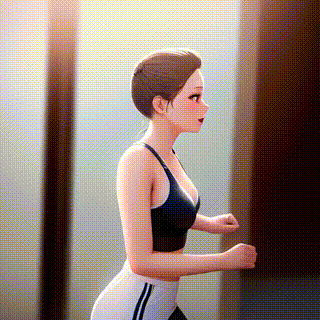
参照動画が必要になります。
動画はPixabayから使わせて頂きました。
こちらの動画です。
import torch from model import Model model = Model(device = "cuda", dtype = torch.float16) model.process_controlnet_canny( prompt='a beautiful girl running', video_path = 'run.mp4', low_threshold=50, high_threshold=50, save_path = 'canny_result.mp4', chunk_size = 2)
Anything-v4.0を使うためにmodel.pyの一部を変更しました。
self.set_model(ModelType.ControlNetCanny,
model_id="local_model/anything-v4.0", controlnet=controlnet)
環境構築
Windows 11 CUDA 11.6 Python 3.10
git clone https://github.com/Picsart-AI-Research/Text2Video-Zero.git cd Text2Video-Zero pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116 pip install -r requirements.txt
関連記事
過去の動画作成に関する記事です。touch-sp.hatenablog.com
touch-sp.hatenablog.com