
「電子工作×深層学習」をテーマとした書籍である。
やはり強化学習の知識は欠かせない。
今回はMXNetで強化学習をしてみた。(GitHubのコードを動かしただけ)
参考にさせて頂いたサイト
環境
Windows10 Pro GPUなし Python 3.8.2
バージョン情報
インストールしたのは「mxnet」「matplotlib」「gym」のみ。
pip install mxnet pip install matplotlib pip install gym
その他は勝手についてくる。
certifi==2020.6.20 chardet==3.0.4 cloudpickle==1.3.0 cycler==0.10.0 future==0.18.2 graphviz==0.8.4 gym==0.17.2 idna==2.6 kiwisolver==1.2.0 matplotlib==3.2.2 mxnet==1.6.0 numpy==1.16.6 pyglet==1.5.0 pyparsing==2.4.7 python-dateutil==2.8.1 requests==2.18.4 scipy==1.5.0 six==1.15.0 urllib3==1.22
強化学習のPythonコード
上記GitHubから「Double_DQN.py」を持ってきた。
episodesを400から360に変更。
あらかじめ「utils.py」と実行コードを同じフォルダに入れておく。
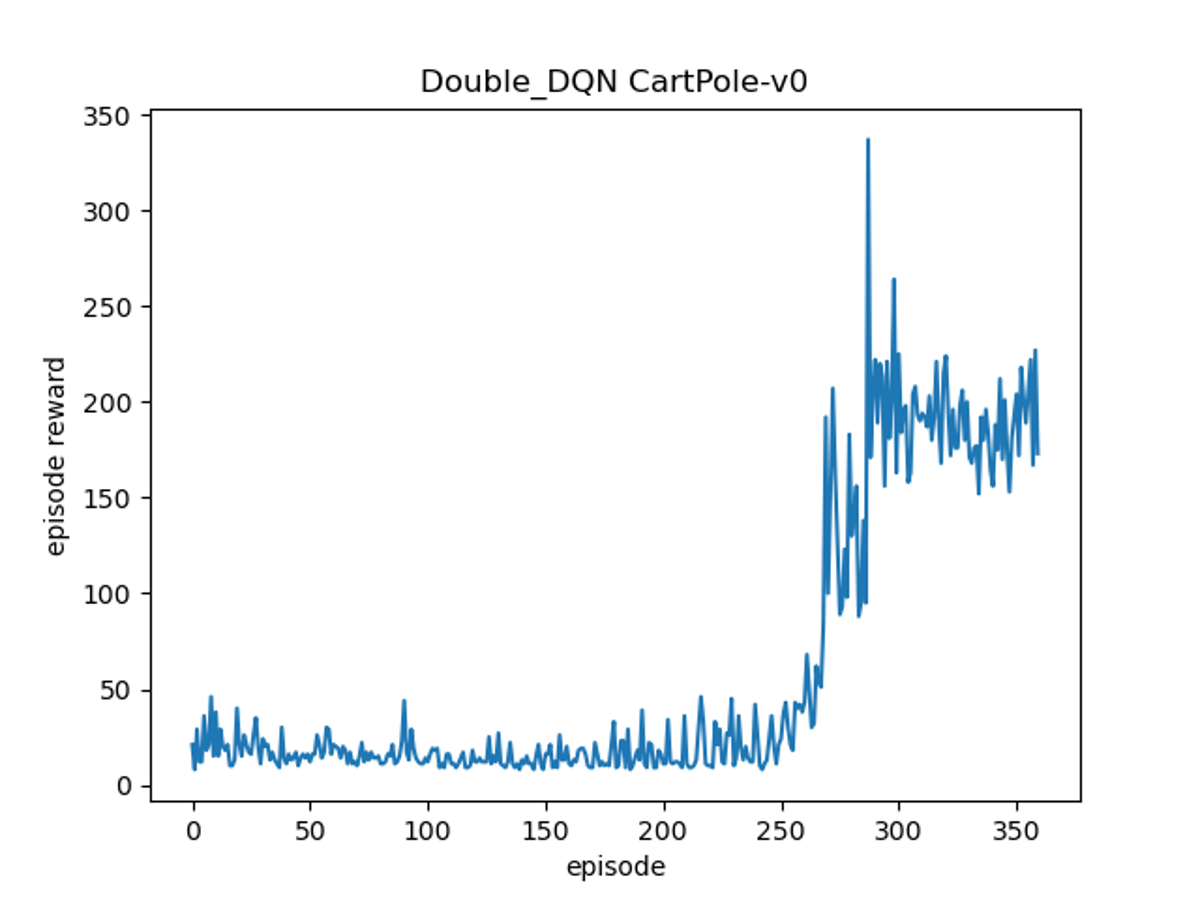
import random import gym import numpy as np import matplotlib.pyplot as plt import mxnet as mx from mxnet import gluon, nd, autograd, init from mxnet.gluon import loss as gloss from utils import MemoryBuffer class DoubleQNetwork(gluon.nn.Block): def __init__(self, n_action): super(DoubleQNetwork, self).__init__() self.n_action = n_action self.dense0 = gluon.nn.Dense(400, activation='relu') self.dense1 = gluon.nn.Dense(300, activation='relu') self.dense2 = gluon.nn.Dense(self.n_action) def forward(self, state): q_value = self.dense2(self.dense1(self.dense0(state))) return q_value class DoubleDQN: def __init__(self, n_action, init_epsilon, final_epsilon, gamma, buffer_size, batch_size, replace_iter, annealing, learning_rate, ctx ): self.n_action = n_action self.epsilon = init_epsilon self.init_epsilon = init_epsilon self.final_epsilon = final_epsilon # discount factor self.gamma = gamma # memory buffer size self.buffer_size = buffer_size self.batch_size = batch_size # replace the parameters of the target network every T time steps self.replace_iter = replace_iter # The number of step it will take to linearly anneal the epsilon to its min value self.annealing = annealing self.learning_rate = learning_rate self.ctx = ctx self.total_steps = 0 self.replay_buffer = MemoryBuffer(self.buffer_size, ctx) # use deque # build the network self.target_network = DoubleQNetwork(n_action) self.main_network = DoubleQNetwork(n_action) self.target_network.collect_params().initialize(init.Xavier(), ctx=ctx) # initialize the params self.main_network.collect_params().initialize(init.Xavier(), ctx=ctx) # optimize the main network self.optimizer = gluon.Trainer(self.main_network.collect_params(), 'adam', {'learning_rate': self.learning_rate}) def choose_action(self, state): state = nd.array([state], ctx=self.ctx) if nd.random.uniform(0, 1) > self.epsilon: # choose the best action q_value = self.main_network(state) action = int(nd.argmax(q_value, axis=1).asnumpy()) else: # random choice action = random.choice(range(self.n_action)) # anneal self.epsilon = max(self.final_epsilon, self.epsilon - (self.init_epsilon - self.final_epsilon) / self.annealing) self.total_steps += 1 return action def update(self): state_batch, action_batch, reward_batch, next_state_batch, done_batch = self.replay_buffer.sample( self.batch_size) with autograd.record(): # get the Q(s,a) all_current_q_value = self.main_network(state_batch) main_q_value = nd.pick(all_current_q_value, action_batch) # different from DQN # get next action from main network, then get its Q value from target network all_next_q_value = self.target_network(next_state_batch).detach() # only get gradient of main network max_action = nd.argmax(all_current_q_value, axis=1) target_q_value = nd.pick(all_next_q_value, max_action).detach() target_q_value = reward_batch + (1 - done_batch) * self.gamma * target_q_value # record loss loss = gloss.L2Loss() value_loss = loss(target_q_value, main_q_value) self.main_network.collect_params().zero_grad() value_loss.backward() self.optimizer.step(batch_size=self.batch_size) def replace_parameters(self): self.main_network.save_parameters('Double_DQN_temp_params') self.target_network.load_parameters('Double_DQN_temp_params') print('Double_DQN parameters replaced') def save_parameters(self): self.target_network.save_parameters('Double_DQN_target_network_parameters') self.main_network.save_parameters('Double_DQN_main_network_parameters') def load_parameters(self): self.target_network.load_parameters('Double_DQN_target_network_parameters') self.main_network.load_parameters('Double_DQN_main_network_parameters') if __name__ == '__main__': seed = 7777777 mx.random.seed(seed) random.seed(seed) np.random.seed(seed) ctx = mx.cpu() env = gym.make('CartPole-v0').unwrapped env.seed(seed) render = False episodes = 360 agent = DoubleDQN(n_action=env.action_space.n, init_epsilon=1, final_epsilon=0.1, gamma=0.99, buffer_size=3000, batch_size=32, replace_iter=1000, annealing=3000, learning_rate=0.0001, ctx=ctx ) episode_reward_list = [] for episode in range(episodes): state = env.reset() episode_reward = 0 while True: if render: env.render() action = agent.choose_action(state) next_state, reward, done, info = env.step(action) episode_reward += reward agent.replay_buffer.store_transition(state, action, reward, next_state, done) if agent.total_steps > 1000: agent.update() if agent.total_steps % agent.replace_iter == 0: agent.replace_parameters() if done: print('episode %d ends with reward %d at steps %d' % (episode, episode_reward, agent.total_steps)) episode_reward_list.append(episode_reward) break state = next_state agent.save_parameters() env.close() plt.plot(episode_reward_list) plt.xlabel('episode') plt.ylabel('episode reward') plt.title('Double_DQN CartPole-v0') plt.savefig('./Double-DQN-CartPole-v0.png') plt.show()
結果の確認
- 未学習
import gym env = gym.make('CartPole-v0') for i in range(10): observation = env.reset() for t in range(300): #env.render() observation, reward, done, info = env.step(env.action_space.sample()) if done: print("Episode{} finished after {} timesteps".format(i, t+1)) break env.close()
Episode0 finished after 19 timesteps Episode1 finished after 25 timesteps Episode2 finished after 11 timesteps Episode3 finished after 19 timesteps Episode4 finished after 15 timesteps Episode5 finished after 37 timesteps Episode6 finished after 22 timesteps Episode7 finished after 11 timesteps Episode8 finished after 13 timesteps Episode9 finished after 17 timesteps
- 学習後
import mxnet as mx from Double_DQN import DoubleQNetwork import gym ctx = mx.cpu() env = gym.make('CartPole-v0') agent = DoubleQNetwork(env.action_space.n) agent.load_parameters('Double_DQN_main_network_parameters') for i in range(10): observation = env.reset() for t in range(300): #env.render() state = mx.nd.array([observation]) action = int(mx.nd.argmax(agent(state), axis=1).asnumpy()) observation, reward, done, info = env.step(action) if done: print("Episode{} finished after {} timesteps".format(i, t+1)) break env.close()
Episode0 finished after 200 timesteps Episode1 finished after 200 timesteps Episode2 finished after 200 timesteps Episode3 finished after 200 timesteps Episode4 finished after 200 timesteps Episode5 finished after 200 timesteps Episode6 finished after 194 timesteps Episode7 finished after 199 timesteps Episode8 finished after 200 timesteps Episode9 finished after 200 timesteps