はじめに
こちらになります。github.com
Gradio画面
Gradioから使ってみました。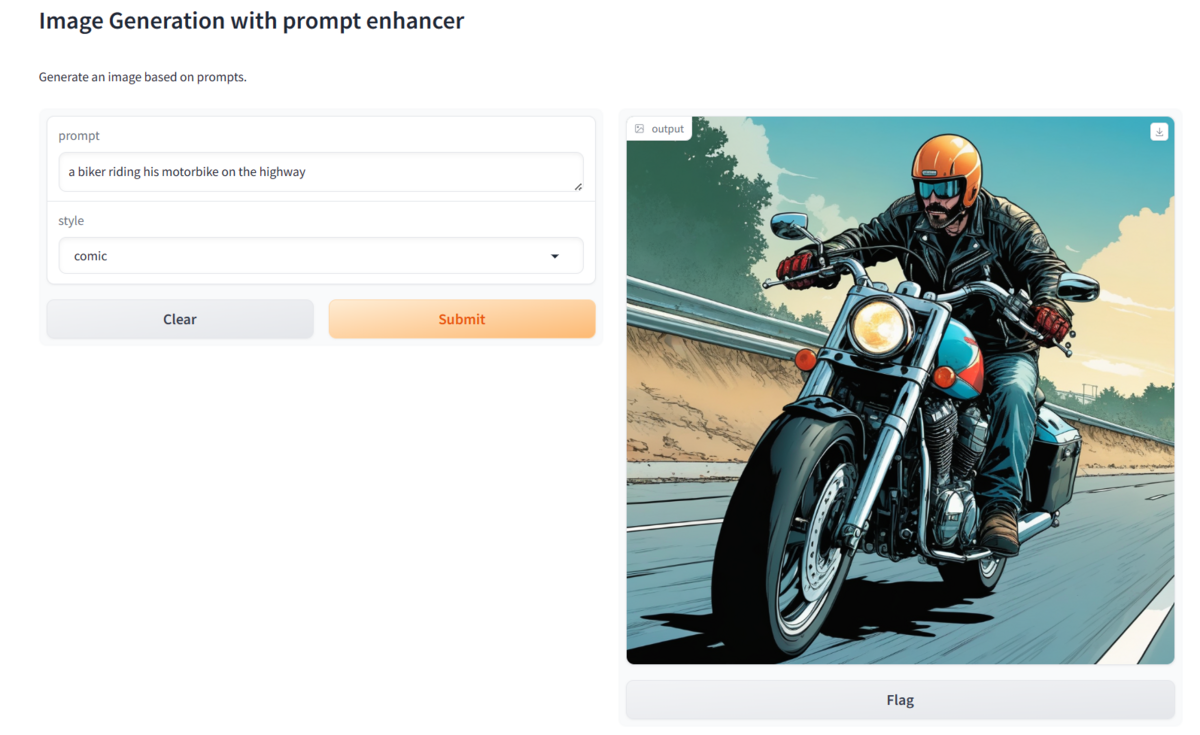
Pythonスクリプト
import torch from transformers import GenerationConfig, GPT2LMHeadModel, GPT2Tokenizer, LogitsProcessor, LogitsProcessorList from diffusers import AutoPipelineForText2Image import gradio as gr styles = { "cinematic": "cinematic film still of {prompt}, highly detailed, high budget hollywood movie, cinemascope, moody, epic, gorgeous, film grain", "anime": "anime artwork of {prompt}, anime style, key visual, vibrant, studio anime, highly detailed", "photographic": "cinematic photo of {prompt}, 35mm photograph, film, professional, 4k, highly detailed", "comic": "comic of {prompt}, graphic illustration, comic art, graphic novel art, vibrant, highly detailed", "lineart": "line art drawing {prompt}, professional, sleek, modern, minimalist, graphic, line art, vector graphics", "pixelart": " pixel-art {prompt}, low-res, blocky, pixel art style, 8-bit graphics", } words = [ "aesthetic", "astonishing", "beautiful", "breathtaking", "composition", "contrasted", "epic", "moody", "enhanced", "exceptional", "fascinating", "flawless", "glamorous", "glorious", "illumination", "impressive", "improved", "inspirational", "magnificent", "majestic", "hyperrealistic", "smooth", "sharp", "focus", "stunning", "detailed", "intricate", "dramatic", "high", "quality", "perfect", "light", "ultra", "highly", "radiant", "satisfying", "soothing", "sophisticated", "stylish", "sublime", "terrific", "touching", "timeless", "wonderful", "unbelievable", "elegant", "awesome", "amazing", "dynamic", "trendy", ] word_pairs = [ "highly detailed", "high quality", "enhanced quality", "perfect composition", "dynamic light" ] def find_and_order_pairs(s, pairs): words = s.split() found_pairs = [] for pair in pairs: pair_words = pair.split() if pair_words[0] in words and pair_words[1] in words: found_pairs.append(pair) words.remove(pair_words[0]) words.remove(pair_words[1]) for word in words[:]: for pair in pairs: if word in pair.split(): words.remove(word) break ordered_pairs = ", ".join(found_pairs) remaining_s = ", ".join(words) return ordered_pairs, remaining_s class CustomLogitsProcessor(LogitsProcessor): def __init__(self, bias): super().__init__() self.bias = bias def __call__(self, input_ids, scores): if len(input_ids.shape) == 2: last_token_id = input_ids[0, -1] self.bias[last_token_id] = -1e10 return scores + self.bias pipe = AutoPipelineForText2Image.from_pretrained( "RunDiffusion/Juggernaut-XL-v9", torch_dtype=torch.float16, variant="fp16" ).to("cuda") pipe.load_lora_weights( "stabilityai/stable-diffusion-xl-base-1.0", weight_name="sd_xl_offset_example-lora_1.0.safetensors", adapter_name="offset", ) pipe.set_adapters(["offset"], adapter_weights=[0.2]) tokenizer = GPT2Tokenizer.from_pretrained("Gustavosta/MagicPrompt-Stable-Diffusion") model = GPT2LMHeadModel.from_pretrained( "Gustavosta/MagicPrompt-Stable-Diffusion", torch_dtype=torch.float16 ).to("cuda") model.eval() generation_config = GenerationConfig( penalty_alpha=0.7, top_k=50, eos_token_id=model.config.eos_token_id, pad_token_id=model.config.eos_token_id, pad_token=model.config.pad_token_id, do_sample=True, ) word_ids = [tokenizer.encode(word, add_prefix_space=True)[0] for word in words] bias = torch.full((tokenizer.vocab_size,), -float("Inf")).to("cuda") bias[word_ids] = 0 processor = CustomLogitsProcessor(bias) proccesor_list = LogitsProcessorList([processor]) def generate_image(prompt, style): prompt = styles[style].format(prompt=prompt) inputs = tokenizer(prompt, return_tensors="pt").to("cuda") token_count = inputs["input_ids"].shape[1] max_new_tokens = 40 - token_count with torch.no_grad(): generated_ids = model.generate( input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"], max_new_tokens=max_new_tokens, generation_config=generation_config, logits_processor=proccesor_list, ) output_tokens = [tokenizer.decode(generated_id, skip_special_tokens=True) for generated_id in generated_ids] input_part, generated_part = output_tokens[0][: len(prompt)], output_tokens[0][len(prompt) :] pairs, words = find_and_order_pairs(generated_part, word_pairs) formatted_generated_part = pairs + ", " + words enhanced_prompt = input_part + ", " + formatted_generated_part image = pipe( enhanced_prompt, width=1024, height=1024, guidance_scale=7.5, num_inference_steps=25, ).images[0] return image app = gr.Interface( fn=generate_image, inputs=[ "text", gr.Dropdown(choices=list(styles.keys()), value=0) ], outputs="image", title="Image Generation with prompt enhancer", description="Generate an image based on prompts.", ) app.launch()