はじめに
待望のSDXL 1.0 (Stable Diffusion XL 1.0) 用ControlNetが公開され始めています。この記事は「Canny」についてです。「Depth」に関してはこちらを見て下さい。touch-sp.hatenablog.com
touch-sp.hatenablog.com
「OpenPose」に関してはこちらを見て下さい。
touch-sp.hatenablog.com
結果
元画像として以前作成したこちらを使いました。
作り方はこちらを見て下さい。
この画像からCanny画像を作成しました。
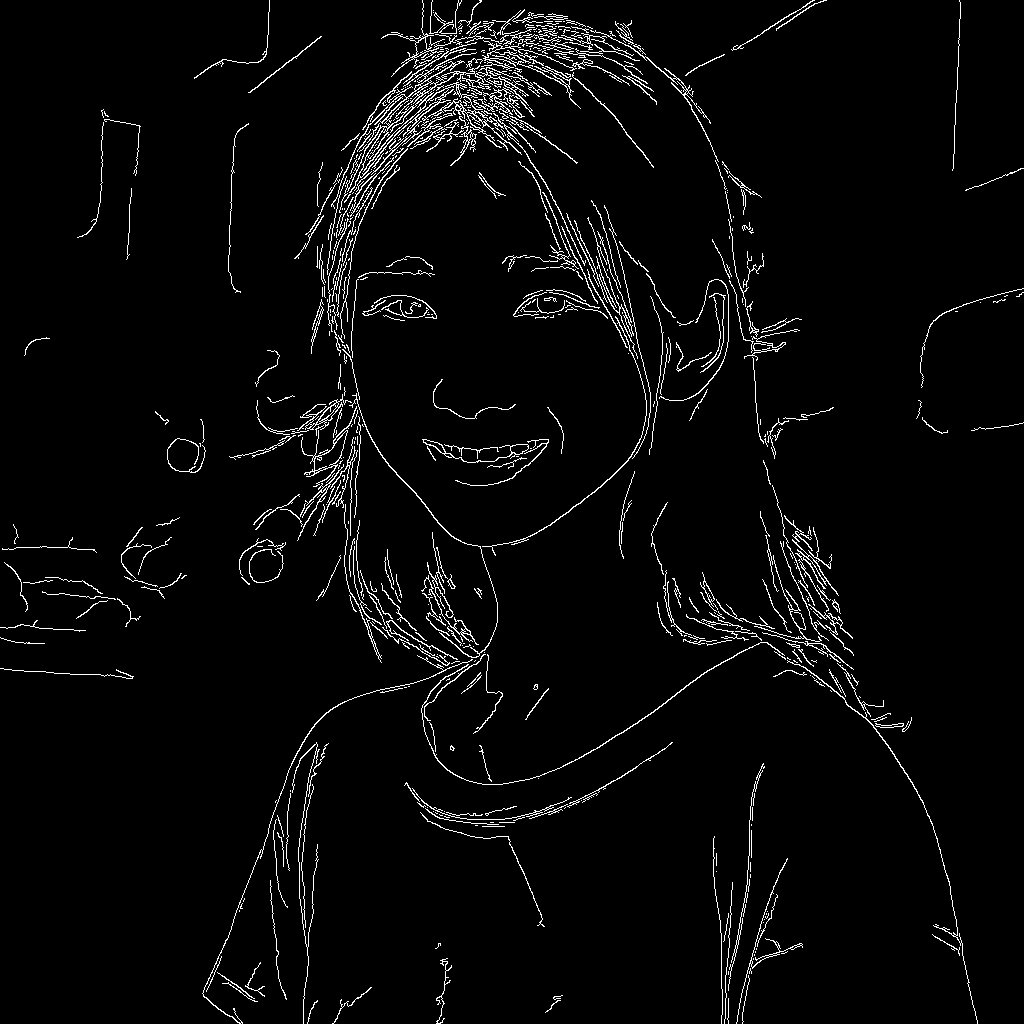
作り方は非常に簡単です。
import cv2 from PIL import Image image = cv2.imread("girl.png") image = cv2.Canny(image, 50, 150) canny_image = Image.fromarray(image)
作成したCanny画像をもとに新たに画像を作りました。

cv2.Cannyの閾値を変えたり、seedを変えたりして画像を作成しました。
「controlnet_conditioning_scale=0.5」は今回変更していません。
Pythonスクリプト
from diffusers import DiffusionPipeline, StableDiffusionXLControlNetPipeline, ControlNetModel import torch import cv2 from PIL import Image controlnet = ControlNetModel.from_pretrained( "diffusers/controlnet-canny-sdxl-1.0", torch_dtype=torch.float16) pipe = StableDiffusionXLControlNetPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-base-1.0", controlnet=controlnet, torch_dtype=torch.float16).to("cuda") refiner = DiffusionPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-refiner-1.0", text_encoder_2=pipe.text_encoder_2, vae=pipe.vae, torch_dtype=torch.float16, variant="fp16", use_safetensors=True).to("cuda") image = cv2.imread("girl.png") image = cv2.Canny(image, 50, 150) canny_image = Image.fromarray(image) prompt = "portrait of japanese girl, 8k, detailed" negative_prompt = "hand, finger, worst quality, low quality" seed = 20000 generator = torch.manual_seed(seed) image = pipe( prompt=prompt, negative_prompt=negative_prompt, controlnet_conditioning_scale=0.5, image=canny_image, generator=generator, output_type="latent").images[0] del pipe image = refiner( prompt=prompt, negative_prompt=negative_prompt, image=image[None, :]).images[0] image.save(f"controlnet_{seed}.png")
SDXL派生モデルとControlNet
続きの記事を書きました。touch-sp.hatenablog.com