結果
左から v1.0 → v1.5 → v2.0 です。

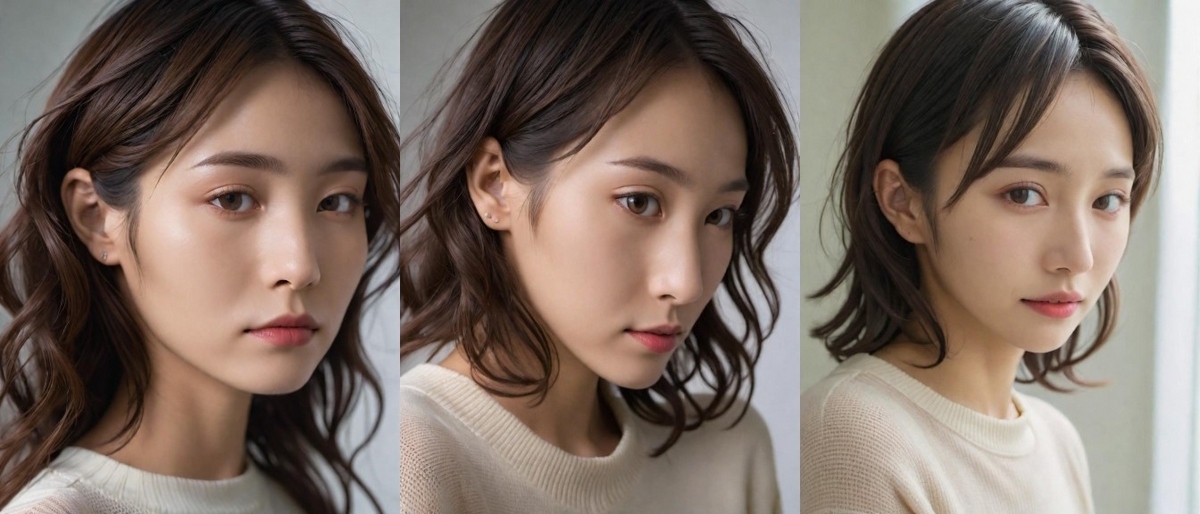


今回使用したプロンプトでは、キリっとしたかっこいい女性から綺麗な女性に変わってきている気がします。
Pythonスクリプト
プロンプトはこちらからそのまま使わせてもらいました。from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler import torch import os import cv2 import numpy as np import time n_samples = 5 model_safetensors = { "v1.0": "model/fudukiMix_v10", "v1.5": "model/fudukiMix_v15", "v2.0": "model/fudukiMix_v20" } def txt2img(model_name:str) -> None: model_path = model_safetensors[model_name] pipe = DiffusionPipeline.from_pretrained( model_path, custom_pipeline = "lpw_stable_diffusion_xl", torch_dtype=torch.float16, variant="fp16" ) pipe.scheduler = DPMSolverMultistepScheduler.from_config( pipe.scheduler.config, algorithm_type="sde-dpmsolver++", use_karras_sigmas=True ) pipe.to("cuda") prompt = "japanese woman, (close-up:2), (natural lighting), wavy hair, forehead, (dark brown eyes), (from side), (downward slanting eyes), pouty, (white sweater), (dyanmic posing), (see-through curtain), (bright room)" n_prompt = "(cleavage:2), (illustration), 3d, 2d, painting, cartoons, sketch, watercolor, monotone, (kimono), (crossed eyes), (strabismus)" os.makedirs(model_name, exist_ok=True) for i in range(n_samples): seed = 100000 * (i + 1) generator = torch.manual_seed(seed) image = pipe( prompt=prompt, negative_prompt=n_prompt, generator=generator, guidance_scale=5.0, num_inference_steps = 35, width=896, height=1152 ).images[0] image.save(os.path.join(model_name, f"{i}.png")) def stack() -> None: os.makedirs("stack_image", exist_ok=True) print(" -> ".join(model_safetensors.keys())) for i in range(n_samples): images_list = [] for key in model_safetensors.keys(): images_list.append(cv2.imread(os.path.join(key, f"{i}.png"))) stack_image = np.hstack(images_list) cv2.imwrite(os.path.join("stack_image", f"{i}.png"), stack_image) if __name__ == "__main__": start = time.time() for model in model_safetensors: txt2img(model) stack() end = time.time() print(f"処理時間: {end - start:.5f}秒")