はじめに
本家の「AnimateAnyone」はこちらです。github.com
本家のサイトではスクリプトや学習済みパラメーターが公開されていません。
今回使用した「Moore-AnimateAnyone」はレポートを参考に作者なりに本家に近づくように作成したモデルのようです。
1枚の画像を用意
こちらの画像を用意しました。
こちらのスクリプトから作成した画像になります。
from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler, AutoencoderKL import torch pipe = DiffusionPipeline.from_pretrained( "model/yabalMixTrue25D_v5", custom_pipeline="lpw_stable_diffusion", vae=AutoencoderKL.from_single_file("vae/vae-ft-mse-840000-ema-pruned.safetensors"), safety_checker=None ) pipe.scheduler = DPMSolverMultistepScheduler.from_config( pipe.scheduler.config, algorithm_type="sde-dpmsolver++", use_karras_sigmas=True ) pipe.to("cuda") prompt = "(masterpiece:1.2), (absurdres:1.2), (best quality:1.2), (looking at viewer), shiny skin, pantyhose, full body, skirt, outdoors, day, countryside, hand on hip, (white|black theme), medium breasts, happy face" neg_prompt = "(worst quality), (low quality), (bad quality), (bad anatomy), (hat:1.2), (cap:1.2), (bag:1.2), greyscale" generator = torch.manual_seed(2024) image = pipe.text2img( prompt=prompt, negative_prompt=neg_prompt, width=512, height=768, max_embeddings_multiples=3, generator=generator ).images[0] image.save("girl.png")
背景の削除

「rembg」を使って背景を削除し、その後ARGBをRGBに変換しました。
こちらで使用した方法をそのまま踏襲しました。
touch-sp.hatenablog.com
ポーズ動画を用意
今回はリポジトリ内にサンプルとして公開してくれているものを使用しました。こちらです。
自分で用意した普通の動画からポーズ動画を作成するスクリプトもリポジトリ内に公開されています。
環境構築とモデルのダウンロード
こちらのGitHubを参照して下さい。github.com
実行
Gradioで実行する場合は以下の1行です。python app.py
結果
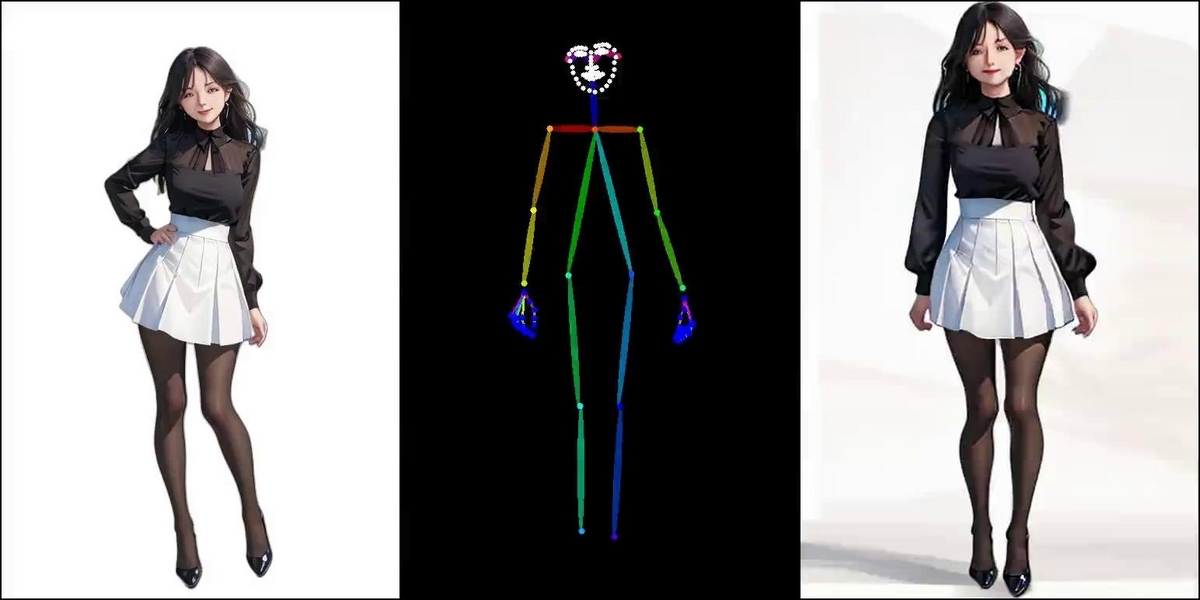
動画はGoogle Bloggerに載せています。
support-touchsp.blogspot.com