公開日:2022年10月31日
最終更新日:2022年11月11日
はじめに
以前、MMOCR学習用のデータを「TextRecognitionDataGenerator」で作りました。github.com
今回PySide6を使って作ってみました。
文字列を画像として保存するだけの簡単なものです。
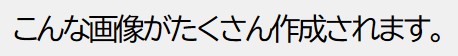

なぜPySide6を使ったか?
Pillowと組み合わせるとラベル上に表示した文字列を画像として保存することが可能だからです。
フォントの種類やサイズ、文字の間隔、余白などをランダムにして様々な画像を作り出しました。
Pythonスクリプト
from PySide6.QtWidgets import QMainWindow, QApplication, QPushButton, QLabel from PySide6.QtGui import QFont from PySide6.QtCore import Qt import os import json import random from PIL import ImageQt, Image class Window(QMainWindow): def __init__(self): super().__init__() self.currentfont = QFont() self.initUI() def initUI(self): self.setWindowTitle("pyQt6 sample") self.button1 = QPushButton('save as image') self.button1.clicked.connect(self.saveimage) self.label_1 = QLabel(self) self.label_1.setAlignment(Qt.AlignmentFlag.AlignCenter | Qt.AlignmentFlag.AlignVCenter) self.setCentralWidget(self.button1) def saveimage(self): data_list = [] for r in range(repeat_n): for i, text in enumerate(texts): self.label_1.setText(text) # Font random_font = random.randrange(0, len(fonts)) fontfamily, bold = fonts[random_font].split(',') self.currentfont.setFamily(fontfamily) self.currentfont.setBold(int(bold)) # Letter spacing random_spacing = random.randrange(start=85, stop=120, step=5) self.currentfont.setLetterSpacing(QFont.PercentageSpacing, random_spacing) # Font size random_font = random.randrange(start=16, stop=22, step=2) self.currentfont.setPointSize(random_font) self.label_1.setFont(self.currentfont) self.label_1.adjustSize() # Margin random_margin = random.randrange(start=4, stop=28, step=8) width = self.label_1.width() + random_margin height = self.label_1.height() + random_margin self.label_1.resize(width, height) image_fname = f'{r}_{i}.jpg' image = ImageQt.fromqpixmap(self.label_1.grab()) #RGBA background = Image.new("RGB", image.size, (255, 255, 255)) background.paste(image, mask=image.split()[3]) # 3 is the alpha channel # Quality random_quality = random.randrange(start=85, stop=100, step=5) background.save(os.path.join('train', image_fname), quality = random_quality) data = { 'img_path': image_fname, 'instances':[{'text':text}] } data_list.append(data) result = { 'metainfo':{ 'dataset_type':'TextRecogDataset', 'task_name':'textrecog' }, 'data_list':data_list } with open('train_labels.json', 'w', encoding='utf-8') as f: json.dump(result, f, indent=2, ensure_ascii=False) if __name__ == "__main__": repeat_n = 3 os.makedirs('train', exist_ok=True) with open('fonts.txt', 'r', encoding='utf-8') as f: lines = f.readlines() fonts = [x.strip() for x in lines] with open('texts.txt', 'r', encoding='utf-8') as f: lines = f.readlines() texts = [x.strip() for x in lines] app = QApplication([]) ex =Window() ex.show() app.exec()
MMOCRですぐに使えるJSONファイルも出力してくれます。
「fonts.txt」をあらかじめ用意する必要があります。このようなものを用意しました。
「0」が標準、「1」がボールド(太字)です。
Arial,0 Arial,1 Courier New,0 Courier New,1 Consolas,0 Consolas,1 BIZ UDPゴシック,0 BIZ UDPゴシック,1 BIZ UDP明朝 Medium,0 Lucida Console,0 UD デジタル 教科書体 N-R,0 UD デジタル 教科書体 NK-R,0 メイリオ,0 メイリオ,1 游明朝,0 游ゴシック,0 游ゴシック,1 MS Pゴシック,0 MS P明朝,0 HGS創英角ゴシックUB,0
ぼかしたり、傾けたり、ノイズをのせたりするのはMMOCRの方でやってくれます。そのため今回のスクリプトには含めていません。
学習時に使用するConfigファイルの以下の部分です。
train_pipeline = [
dict(
type='LoadImageFromFile',
file_client_args=dict(backend='disk'),
ignore_empty=True,
min_size=2),
dict(type='LoadOCRAnnotations', with_text=True),
dict(type='Resize', scale=(200, 32), keep_ratio=False),
dict(
type='RandomApply',
prob=0.5,
transforms=[
dict(
type='RandomChoice',
transforms=[
dict(
type='RandomRotate',
max_angle=5,
),
])
],
),
dict(
type='RandomApply',
prob=0.25,
transforms=[
dict(type='PyramidRescale'),
dict(
type='mmdet.Albu',
transforms=[
dict(type='GaussNoise', var_limit=(20, 20), p=0.5),
dict(type='MotionBlur', blur_limit=5, p=0.5),
]),
]),
dict(
type='RandomApply',
prob=0.25,
transforms=[
dict(
type='TorchVisionWrapper',
op='ColorJitter',
brightness=0.5,
saturation=0.5,
contrast=0.5,
hue=0.1),
]),
dict(
type='PackTextRecogInputs',
meta_keys=('img_path', 'ori_shape', 'img_shape', 'valid_ratio'))
]
結果
実際に学習させたところ問題なく学習可能でした。結果も良好でした。関連記事
touch-sp.hatenablog.com補足(ノイズの追加)
すでに作成した画像に後からノイズをのせるためのスクリプトを記述しました。import time import os import glob from PIL import Image import numpy as np os.makedirs('train_with_noise', exist_ok=True) start_time = time.time() imgs = glob.glob('train/*.jpg') for img in imgs: fname = os.path.basename(img) original_img = np.array(Image.open(img)) noise = np.random.normal(0, 3, original_img.shape) img_with_noise = Image.fromarray((original_img + noise).astype('uint8')) img_with_noise.save(os.path.join('train_with_noise', fname)) finish_time = time.time() print(f'time: {finish_time - start_time} sec')
上記スクリプトは画像数が多いと時間がかかります。
「threading」を使って簡易的に処理を分散させたスクリプトがこちらです。
import time import os import glob from PIL import Image import numpy as np import threading thread_count = 6 save_dir = 'train_with_noise3' os.makedirs(save_dir, exist_ok=True) def add_noise(img_list): for img in img_list: fname = os.path.basename(img) original_img = np.array(Image.open(img)) noise = np.random.normal(0, 3, original_img.shape) img_with_noise = Image.fromarray((original_img + noise).astype('uint8')) img_with_noise.save(os.path.join(save_dir, fname)) start_time = time.time() imgs = glob.glob('train/*.jpg') img_num = int(len(imgs) / thread_count) thread_list = [] for i in range(thread_count): if i != thread_count -1: thread_list.append(threading.Thread(target=add_noise, args=(imgs[(img_num * i):(img_num* (i + 1))],))) else: thread_list.append(threading.Thread(target=add_noise, args=(imgs[(img_num * i):],))) for each_thread in thread_list: each_thread.start() for each_thread in thread_list: each_thread.join() finish_time = time.time() print(f'time: {finish_time - start_time} sec')
スクリプトの改良
新しい記事を書きました。touch-sp.hatenablog.com