はじめに
前回ReazonSpeechを使うためのGUIをC#で作りました。touch-sp.hatenablog.com
今回はGradioを使いPythonだけで完結させようと思います。
PC環境
Windows 11 Python 3.11 CUDA 11.8
Python環境構築
ReazonSpeechと最新のGradioは共存できませんでした。ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. reazonspeech-nemo-asr 2.1.0 requires huggingface-hub<0.24, but you have huggingface-hub 0.26.0 which is incompatible.
以下でうまくいきました。
pip install torch==2.5.0+cu118 --index-url https://download.pytorch.org/whl/cu118 pip install cython git clone https://github.com/reazon-research/ReazonSpeech pip install ReazonSpeech/pkg/nemo-asr pip install gradio==4.44.1
Pythonスクリプト
import gradio as gr import soundfile as sf from reazonspeech.nemo.asr import load_model, transcribe, audio_from_path import tempfile import os model = load_model() def transcribe_audio(audio): # 一時ファイルを作成して音声データを保存 with tempfile.NamedTemporaryFile(delete=False, suffix=".wav") as temp_audio: sf.write(temp_audio.name, audio[1], audio[0]) temp_audio_path = temp_audio.name # 音声認識の実行 audio = audio_from_path(temp_audio_path) ret = transcribe(model, audio) text = ret.text # 一時ファイルの削除 os.unlink(temp_audio_path) return text iface = gr.Interface( fn=transcribe_audio, inputs=gr.Audio(sources=["microphone"]), outputs="text", title="音声録音と文字起こし", description="マイクから音声を録音し、文字起こしを行います。", examples=[], ) if __name__ == "__main__": iface.launch()
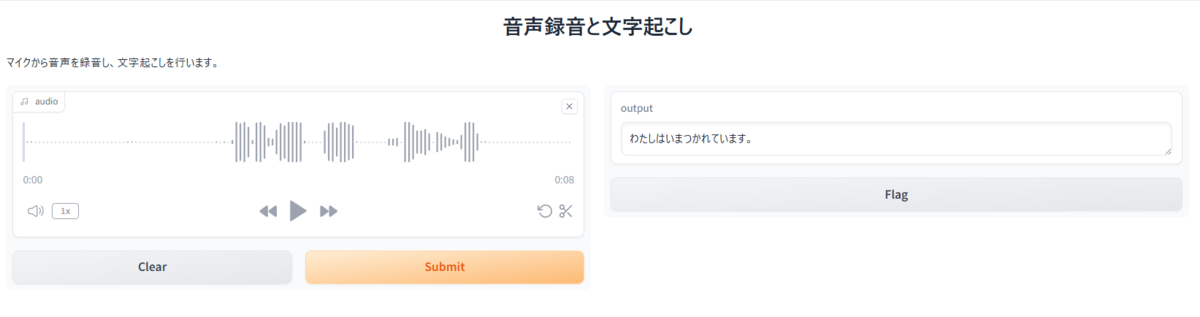
実行画面