前回の続きです。
touch-sp.hatenablog.com
データ準備はGPU非搭載のパソコンで行ったが、学習はGPU搭載パソコンで行った。
Windows10 Pro Visual Studio 2019 communityインストール済み(←たぶんこれが必要?) NVIDIA GeForce GTX1080 Python 3.7.9 CUDA 10.1
もしVisual Studioをインストールしていなくて後述のスクリプトが再現できなければ、試しにインストールしてみるのが良い。
Visual Studioは2017でも良いかもしれない。
Visual Studioはcommunity版であれば無料でインストールできる。
またVisual Studioが必要だとして、Visual Studioの中のどれが必要でどれが必要でないかはよくわからない。
とりあえず自分がインストールしているのは以下の通り。
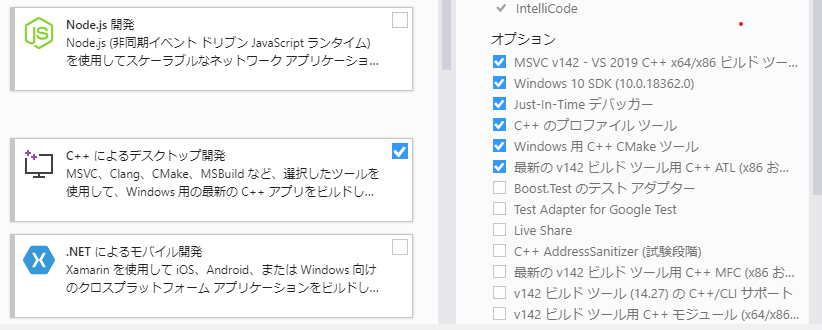
環境構築
「mxnet-cu101」と「gluoncv」のみインストールした。その他は勝手についてきた。
cuDNNは別途入れていない。(こちらを参照)
pip install mxnet-cu101==1.7.0 -f https://dist.mxnet.io/python/cu101 pip install gluoncv
certifi==2020.6.20 chardet==3.0.4 cycler==0.10.0 gluoncv==0.8.0 graphviz==0.8.4 idna==2.6 kiwisolver==1.2.0 matplotlib==3.3.2 mxnet-cu101==1.7.0 numpy==1.16.6 Pillow==8.0.1 portalocker==2.0.0 pyparsing==2.4.7 python-dateutil==2.8.1 pywin32==228 requests==2.18.4 scipy==1.5.3 six==1.15.0 tqdm==4.50.2 urllib3==1.22
学習のためのPythonスクリプト
import time import mxnet as mx from mxnet import gluon, autograd from mxnet.gluon.data import DataLoader from gluoncv import model_zoo from gluoncv.data import VOCDetection from gluoncv.data.transforms import presets from gluoncv.data.batchify import Tuple, Stack from gluoncv.loss import SSDMultiBoxLoss ctx = [mx.gpu()] classes = ['face'] net = model_zoo.get_model('ssd_512_mobilenet1.0_voc', pretrained=True, ctx = ctx[0], root='./models') net.reset_class(classes) net.hybridize() x = mx.nd.zeros(shape=(1, 3, 512, 512),ctx=ctx[0]) with autograd.train_mode(): _, _, anchors = net(x) batch_size = 16 num_workers = 0 epochs = 5 width, height = 512, 512 train_transform = presets.ssd.SSDDefaultTrainTransform(width, height, anchors.as_in_context(mx.cpu())) batchify_fn = Tuple(Stack(), Stack(), Stack()) VOCDetection.CLASSES = ['head'] train_dataset = VOCDetection(root='VOCdevkit',splits=((2012, 'train'),)) train_loader = DataLoader( train_dataset.transform(train_transform), batch_size, shuffle=True, batchify_fn=batchify_fn, last_batch='rollover', num_workers=num_workers) mbox_loss = SSDMultiBoxLoss() ce_metric = mx.metric.Loss('CrossEntropy') smoothl1_metric = mx.metric.Loss('SmoothL1') trainer = gluon.Trainer( net.collect_params(), 'sgd', {'learning_rate': 0.001, 'wd': 0.0005, 'momentum': 0.9}) for epoch in range(epochs): ce_metric.reset() smoothl1_metric.reset() tic = time.time() btic = time.time() for i, batch in enumerate(train_loader): batch_size = batch[0].shape[0] data = gluon.utils.split_and_load(batch[0], ctx_list=ctx, batch_axis=0) cls_targets = gluon.utils.split_and_load(batch[1], ctx_list=ctx, batch_axis=0) box_targets = gluon.utils.split_and_load(batch[2], ctx_list=ctx, batch_axis=0) with autograd.record(): cls_preds = [] box_preds = [] for x in data: cls_pred, box_pred, _ = net(x) cls_preds.append(cls_pred) box_preds.append(box_pred) sum_loss, cls_loss, box_loss = mbox_loss( cls_preds, box_preds, cls_targets, box_targets) autograd.backward(sum_loss) trainer.step(1) ce_metric.update(0, [l * batch_size for l in cls_loss]) smoothl1_metric.update(0, [l * batch_size for l in box_loss]) name1, loss1 = ce_metric.get() name2, loss2 = smoothl1_metric.get() if i % 20 == 0: print('[Epoch {}][Batch {}], Speed: {:.3f} samples/sec, {}={:.3f}, {}={:.3f}'.format( epoch, i, batch_size/(time.time()-btic), name1, loss1, name2, loss2)) btic = time.time() net.save_parameters('ssd_512_mobilenet1.0_face.params')
上記を実行すると「ssd_512_mobilenet1.0_face.params」というファイルが保存される。
結果の確認
from matplotlib import pyplot as plt from gluoncv import model_zoo, data, utils url = 'https://raw.githubusercontent.com/dmlc/web-data/master/gluoncv/segmentation/mhpv1_examples/1.jpg' filename = 'mhp_v1_example.jpg' utils.download(url, filename) classes = ['face'] net = model_zoo.get_model('ssd_512_mobilenet1.0_voc', pretrained=True, root='./models') net.reset_class(classes) net.load_parameters('ssd_512_mobilenet1.0_face.params') x, image = data.transforms.presets.ssd.load_test(filename, 512) cid, score, bbox = net(x) ax = utils.viz.plot_bbox(image, bbox[0], score[0], cid[0], class_names=classes) plt.axis('off') plt.show()

うまくいったと思う。
自分の環境では学習は5分程度で終了した。
はまった点
VOCDetection.CLASSES = ['head']
これでVOCDetectionのクラスを強制的に変更しているが、この一文をモデルをロードする前に持ってくるとエラーがでた。
net = model_zoo.get_model('ssd_512_mobilenet1.0_voc', pretrained=True, ctx = ctx[0], root='./models')
anchorsがGPU上にのっているとエラーがでた。
そのためCPU上に移すことが必要であった。
train_transform = presets.ssd.SSDDefaultTrainTransform(width, height, anchors.as_in_context(mx.cpu()))
なぜ trainer.step(batch size)ではなくtrainer.step(1)なのか?
チュートリアルには以下のような説明がありました。
since we have already normalized the loss, we don't want to normalize by batch-size anymore